数据库的索引原理。
为什么需要索引
假设以下查询:
1 | SELECT * FROM Employee |
如果没有索引,则需要对整张表进行遍历,效率极低。因此,索引是通过极大地减少需要检索的行/记录数的方式,来加速查询检索的速度。
索引的定义
索引是一个数据结构(一般情况下是 B-Tree),其储存了表特定列的值。
B-Tree
B-Tree 是最常用的索引数据结构,因为其非常高效:
- 所有的查找、删除、插入指令都能在对数(log)时间内完成;
- 储存的数据可以进行排序。
B-Tree 本质上是一种平衡多叉树,其对子节点的数量限制是维持一个区间,因此可以避免过于频繁地树结构调整,保持一定的灵活性,但是也会引入一些空间冗余。
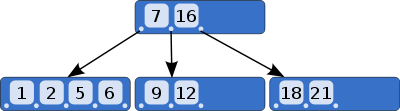
Hash Table
Hash Table 是另外一种可以用于索引的数据结构,原因同样是其在进行查找时,非常高效。
例如,上面的查询语句,Hash Table 可以存储这样的键值:
1 | <Key:Jesus, Value:0x28938> |
其中,Value存储的内存中的指针,指向硬件中数据表的某行,这样通过Key就可以快速查找到该行。
但是,Hash Table 也有其缺点,就是其 Key 是不能进行排序的。因此,类似这样的查询是无法支持的。
1 | age > 40 |
R-Tree
R-Tree 常用于空间/距离相关问题的索引数据结构。例如,“查找附近两公里内的星巴克”。 R-Tree 本质上是将空间分割成一个一个矩形,再建立矩形包含关系的平衡多叉树 B-Tree ,这样查找的时候,就能利用 B-Tree 的优点进行距离的快速检索。
Bitmap
Bitmap 常用于Boolean型值的列。
举例:
| Name | Sex | Marital |
|---|---|---|
| Jay | Male | Unmarried |
| Jolin | Female | UnMarried |
| Kobe | Male | Married |
如果要查询:
1 | select * from table where Sex = 'Male' and Marital = 'Married' |
使用 Bitmap 进行标识, 然后进行AND位操作即可:
| RowID | 1 | 2 | 3 |
|---|---|---|---|
| Sex | 1 | 0 | 1 |
| Marital | 0 | 0 | 1 |
| AND | 0 | 0 | 1 |
索引的原理
以 B-Tree 为例,其可以通过对某列值进行排序,并存储指向该行的指针,因此,在进行查找操作时,可以通过排序完的数据集进行快速查找,并通过指针获取到对应该行的其他数据。
索引的使用
创建单列索引
SQL 语句:
1 | CREATE INDEX name_index |
创建多列索引
SQL 语句:
1 | CREATE INDEX name_index |
是否使用索引
数据库会先衡量是否存在索引,如果存在,再计算索引的命中率。在某些情境下,使用索引并不如直接检索全表,例如:
| Sex |
|---|
| Male |
| Female |
对于这一列,实际上,只有两种值,Male 和 Female,索引命中率计算公式为:
$$Selectivity\ of\ index = cardinality\ /\ (number\ of\ records) * 100\%$$
假设表有10000行,cardinality 代入 2, 计算结果为:0.02%,非常低,这种情况下,实际上,使用索引并不能提升效率。例如,我们要查找 Famele 的行,那么很可能有5000行满足条件,使用索引需要耗时,并且消耗资源,访问索引5000次,远不如直接检索全表来得快。
索引的代价
使用索引需要额外的代价:
- 占用空间:索引是一种数据结构,其存储需要占用空间;
- 需要更新:添加、删除或者更新数据时,同时需要更新索引。