This chapter we study the conceptual and implementation aspects of network applications.
Principles of Network Applications
Network Application Architectures
The application architecture is designed by the application developer and dictates how the application is structured over the various end systems.
client-server architecture, P2P(peer-to-peer) architecture
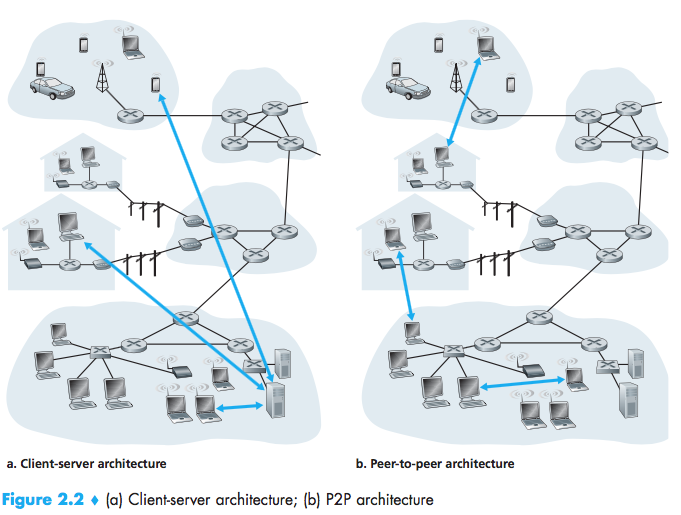
P2P:self-scalability(compelling features), but three major chanllenges:
- ISP Friendly:P2P video streaming and file distribu-tion applications shift upstream traffic from servers to residential ISPs, thereby putting significant stress on the ISPs;
- Security:distributed and open nature;
- Incentives:convincing users to volunteer bandwidth, storage, and computation resources.
Processes Communicating
In the context of a communication session between a pair of processes, the process that initiates the communication is labeled as the client. The process that waits to be contacted to begin the session is the server.
Port Number:identify the receiving process (more specifically, the receiving socket) running in the host.
Transport Services Available to Applications
Reliable Data Transfer
Reliable Data Transfer:a protocol provides such a guaranteed data delivery service.
loss-tolerant applications
Throughput
Throughput:the rate at which the sending process can deliver bits to the receiving process.
bandwidth-sensitive applications:Multimedia applications.
elastic applications:electronic mail, file transfer, and Web transfers.
Timing
timing guarantees.
Security
- encrypt
- decrypt
- data integrity
- end-point authentication**
Transport Services Provided by the Internet
TCP Services
- Connection-oriented service:Handshaking;
- Reliable data transfer service:all data sent without error and in the proper order;
- Secure Sockets Layer (SSL):TCP-enhanced-with-SSL not only does everything that traditional TCP does but also provides critical process-to-process security services, including
encryption, data integrity, and end-point authentication; - congestion-control mechanism.
UDP Services
- connectionless
- unreliable data transfer service
Services Not Provided by Internet Transport Protocols
Today’s Internet can often provide satisfactory service to time-sensitive applications, but it cannot provide any timing or throughput guarantees.
Many firewalls are configured to block (most types of) UDP traffic, Internet telephony applications often are designed to use TCP as a backup if UDP communication fails.
The Web and HTTP
Overview of HTTP
HyperText Transfer Protocol (HTTP):defines how Web clients request Web pages from Web servers and how servers transfer Web pages to clients.
HTTP:
- uses TCP:as its underlying transport protocol;
- stateless:an HTTP server maintains no informa- tion about the clients.
Non-Persistent and Persistent Connections
Non-persistent Connections:each request/response pair be sent over a separate TCP connection.
Persistent Connections:all of the requests and their cor-responding responses be sent over the same TCP connection.
Although HTTP uses persistent connections in its default mode, HTTP clients and servers can be configured to use non-persistent connections instead.
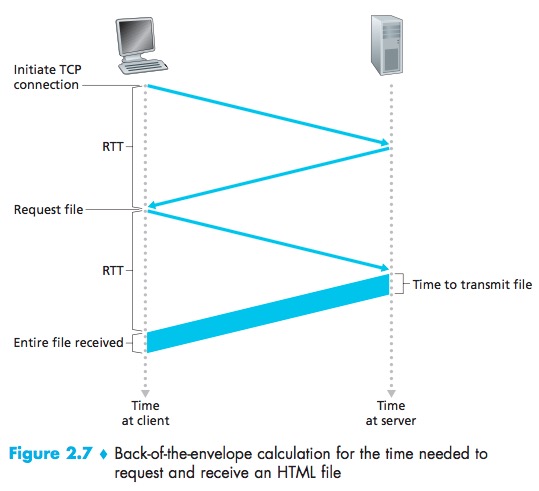
HTTP with Non-Persistent Connections
Round-trip Time(RTT):the time it takes for a small packet to travel from client to server and then back to the client.
Note that each TCP connection transports exactly one request mes-sage and one response message.
HTTP with Persistent Connections
HTTP server closes a con-nection when it isn’t used for a certain time.
HTTP Message Format
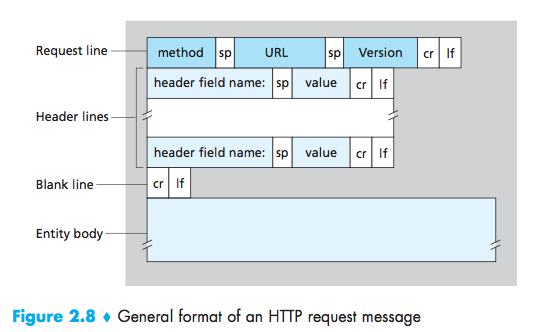
HTTP Request Message
1 | GET /somedir/page.html HTTP/1.1 //request line:three fields(the method field, the URL field, and the HTTP version field) |
- GET:used when the browser requests an object, with the requested object iden-tified in the URL field;
- HEAD:it responds with an HTTP message but it leaves out the requested object;Application developers often use the HEAD method for debug-ging;
- POST:when a user fills out a form;
- PUT:often used in conjunction with Web publishing tools. It allows a user to upload an object to a specific path (directory) on a specific Web server;The PUT method is also used by applications that need to upload objects to Web servers;
- DELETE:allows a user, or an application, to delete an object on a Web server.
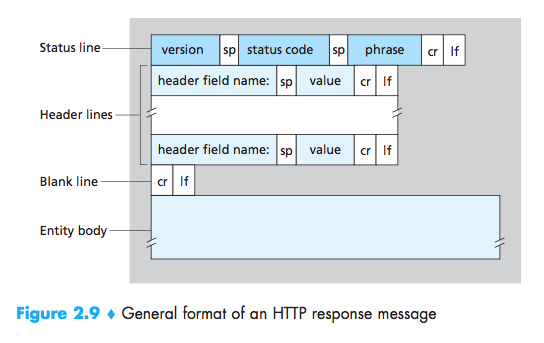
HTTP Response Message
1 | HTTP/1.1 200 OK //status line:three fields(the protocol ver-sion field, a status code, and a corresponding status message) |
- 200 OK: Request succeeded and the information is returned in the response.
- 301 Moved Permanently: Requested object has been permanently moved;the new URL is specified in Location: header of the response message. Theclient software will automatically retrieve the new URL.
- 400 Bad Request: This is a generic error code indicating that the requestcould not be understood by the server.
- 404 Not Found: The requested document does not exist on this server.
- 505 HTTP Version Not Supported: The requested HTTP protocolversion is not supported by the server.
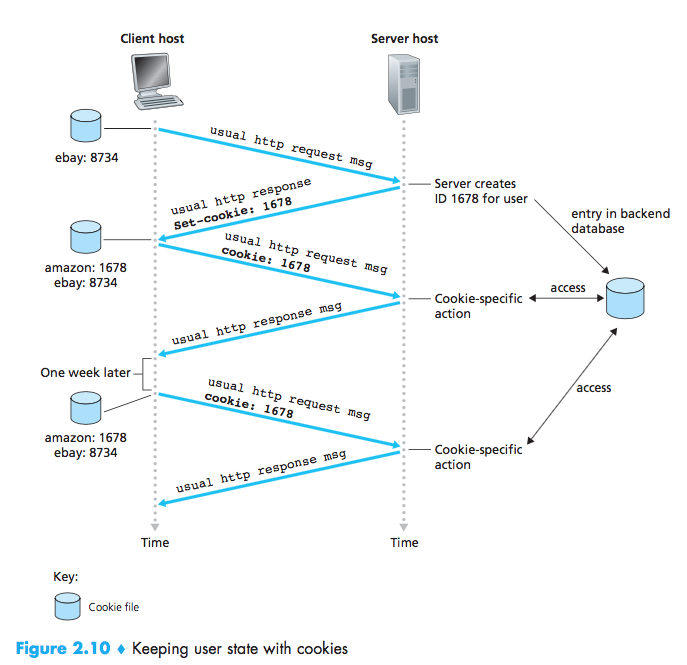
User-Server Interaction: Cookies
HTTP uses cookies, defined in [RFC 6265], allow sites to keep track of users, but also be considered as an invasion of privacy.
cookie technology has four components:
- a cookie header line in the HTTP response message;
- a cookie header line in the HTTP request message;
- a cookie file kept on the user’s end system and managed by the user’s browser;
- a back-end database at the Web site.
Web Caching
A Web cache also called a proxy server-is a network entity that satisfies HTTP requests on the behalf of an origin Web server.
Typically a Web cache is purchased and installed by an ISP.
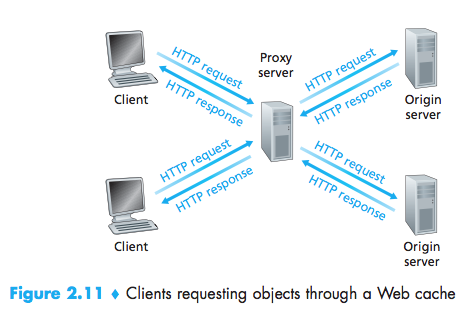
- a Web cache can substantially reduce the response time for a client request;
- Web caches can substantially reduce traffic on an institution’s access link to the Internet. By reducing traffic, the institution does not have to upgrade bandwidth as quickly, therebyreducing costs.
Content Distribution Networks (CDNs):A CDN company installs many geographically distributed caches throughout the Internet, thereby localizing much of the traffic.
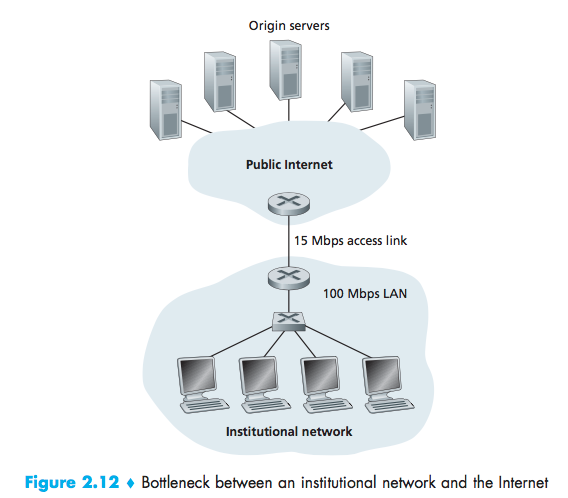
Internet delay:the amount of time it takes from when the router on the Internet side of the access link forwards an HTTP request (within an IP datagram) until it receives the response (typically within many IP datagrams) is two seconds on average.
The Conditional GET
Conditional GET:a mechanism that allows a cache to verify that its objects are up to date.
- the request message uses the GET method;
- the request message includes an If-Modified-Since: header line.
Request:
1 | GET /fruit/kiwi.gif HTTP/1.1 |
Response:
1 | HTTP/1.1 304 Not Modified |
File Transfer: FTP
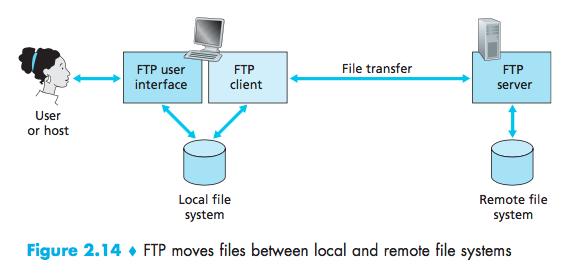
FTP is said to send its control information out-of-band. HTTP, as you recall, sends requestand response header lines into the same TCPconnection that carries the transferredfile itself.
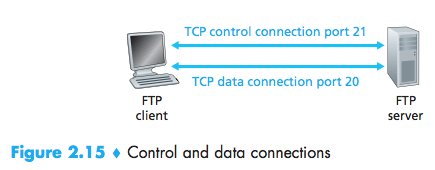
- The client side of FTP(user) first initiates a control TCP connection with the server side (remote host) on server port number 21.
- The client side of FTP sends the user identification and password over this control connection.
- The client side of FTP also sends, over the control connection, commands to change the remote directory.
- When the server side receives a command for a file transfer over the control connection (either to, or from, the remote host), the server side initiates a TCP data connection to the client side.
- FTP sends exactly one file over the data connection and then closes the data connection.
- If, during the same session, the user wants to transfer another file, FTP opens another data connection. Thus, with FTP, the control connection remains open throughout the duration of the user session, but a new data connec-tion is created for each file transferred within a session (that is, the data connec-tions are non-persistent).
FTP maintain state about the user
Keeping track of this state information for each ongoing user session significantly constrains the total number of sessions that FTP can maintain simultaneously.
FTP Commands and Replies
Commands:
1 | USER username: Used to send the user identification to the server. PASS password: Used to send the user password to the server. LIST: Used to ask the server to send back a list of all the files in the current remote directory. The list of files is sent over a (new and non-persistent) data connection rather than the control TCP connection. |
Replies:
1 | 331 Username OK, password required 125 Data connection already open; transfer starting |
Electronic Mail in the Internet
Simple Mail Transfer Protocol (SMTP)
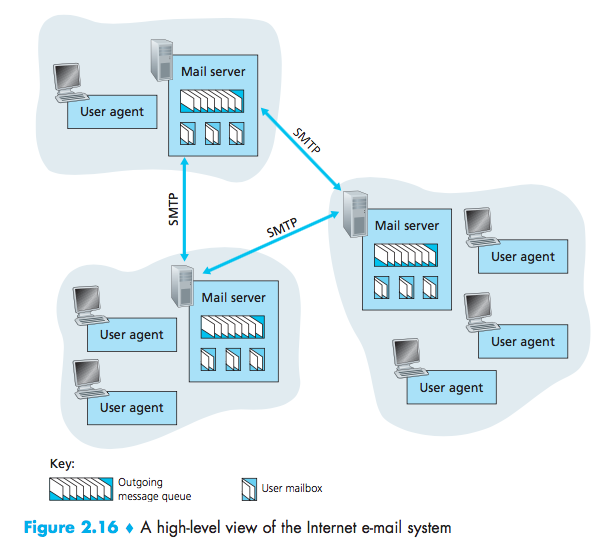
Mail server must also deal with failures in other mail server:
- If a server cannot deliver mail, it will hold the message in a message queue and attempts to transfer the message later;
- Reattempts are often done every 30 minutes or so;
- If there is no success after several days, the server removes the message and notifies the sender with an e-mail message.
SMTP
It requires binary multimedia data to be encoded to ASCII before being sent over SMTP.
SMTP has TCP establish a connection to port 25.
1 | S: 220 hamburger.edu C: HELO crepes.fr S: 250 Hello crepes.fr, pleased to meet you C: MAIL FROM: <alice@crepes.fr> S: 250 alice@crepes.fr ... Sender ok C: RCPT TO: <bob@hamburger.edu> S: 250 bob@hamburger.edu ... Recipient ok C: DATA S: 354 Enter mail, end with “.” on a line by itself C: Do you like ketchup? C: How about pickles? C: . S: 250 Message accepted for delivery C: QUIT S: 221 hamburger.edu closing connection |
SMTP commands:
- HELO
- MAIL FROM
- RCPT TO
- DATA
- CRLF.CRLF
- QUIT
Comparison with HTTP
SMTP is primarily a push protocol, HTTP is mainly a pull protocol;
SMTP requires each message, including the body of each message, to be in 7-bit ASCII format.
HTTP encapsulates each object in its own HTTP response message. Internet mail places all of the message’s objects into one message.
Mail Message Formats
1 | From: alice@crepes.fr To: bob@hamburger.edu Subject: Searching for the meaning of life. |
Mail Access Protocols
popular mail access protocols, including Post Office Protocol—Version 3 (POP3), Internet Mail Access Protocol (IMAP), and HTTP.
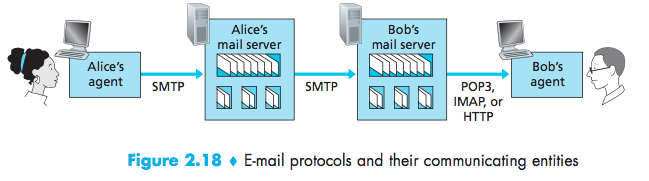
POP3
POP3 begins when the user agent opens a TCP connection to the mail server on port 110.
POP3 progresses through three phases:
- authorization:the user agent sends a username and a password (in the clear) to authenticate the user;
- transaction:the user agent retrieves messages, and mark messages for deletion, remove deletion marks, and obtain mail statistics;
- update:occurs after the client has issued the quit command, ending the POP3 session.
responses:
- +OK:used by the server to indicate that the previous command was fine;
- -ERR:used by the server to indicate that something was wrong with the previous command.
1 | telnet mailServer 110 |
A user agent using POP3 can often be configured (by the user) to :
- download and delete:The user agent retrieves and deletes each message from the server.Four commands:list, retr, dele, and quit.
- download and keep:the user agent leaves the messages on the mail server after downloading them. In this case, He can reread messages from different machines.
1 | C: list S: 1 498 S: 2 912 S: . C: retr 1 S: (blah blah ... S: ................. S: ..........blah) S: . C: dele 1 C: retr 2 S: (blah blah ... S: ................. S: ..........blah) S: . C: dele 2 C: quit S: +OK POP3 server signing off |
The POP3server maintains some state information; in particular, it keeps track of which usermessages have been marked deleted. However, the POP3 server does not carry stateinformation across POP3 sessions.
IMAP
The IMAP protocol provides commands to allow users to create folders and move messages from one folder to another. IMAP also provides commands that allow users to search remote folders for messages matching specific criteria.
Unlike POP3, an IMAP server maintains user state information across IMAP sessions.Another important feature of IMAP is that it has commands that permit a user agent to obtain components of messages.
Web-Based E-Mail
The e-mail message is sent from web browser to mail server over HTTP rather than over SMTP.
DNS—The Internet’s Directory Service
Services Provided by DNS
domain name system (DNS):a directory service that translates hostnames to IPaddresses, and some other services.
The DNS is:
- (1) a distributed database implemented in a hierarchy of DNS servers;
- (2) an application-layer protocol that allows hosts to query the distributed database.
- (3)The DNS servers are often UNIX machines running the Berkeley Internet NameDomain (BIND) software [BIND 2012].
The DNS protocol runs over UDP and usesport 53.
A “nearby” DNS server:cache IP address, which helps to reduce DNS network traffic as well as the average DNS delay.
DNS provides a few other services:
- Host aliasing:canonical hostname;
- Mail server aliasing:the MX record permits a company’s mail server and Web server to have identical(aliased) hostnames;for example, a company’s Web server and mail server can both be called enterprise.com;
- Load distribution:The DNS database contains a set of IPaddresses that associated with one canonical hostname. When clients make a DNS query for a namemapped to a set of addresses, the server responds with the entire set of IPaddresses, but rotates the ordering of the addresses within each reply.
Overview of How DNS Works
A simple design for DNS would have one DNS server that contains all the map- pings:
- A single point of failure;
- Traffic volume;
- Distant centralized database;
- Maintenance.
A Distributed, Hierarchical Database
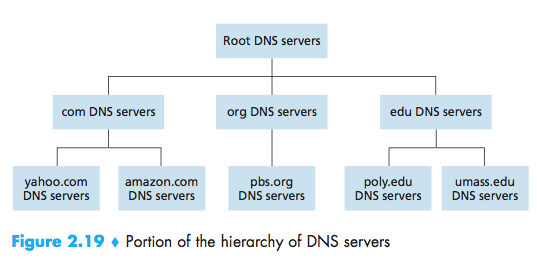
- Root DNS server:Although we have referred to eachof the 13 root DNS servers as if it were a single server, each “server” is actuallya network of replicated servers, for both security and reliability purposes;
- Top-level domain (TLD) servers:These servers are responsible for top-leveldomains such as com, org, net, edu, and gov, and all of the country top-level domainssuch as uk, fr, ca, and jp;
- Authoritative DNS servers:An organiza-tion’s authoritative DNS server houses these DNS records.
Local DNS server:When ahost connects to an ISP, the ISP provides the host with the IP addresses of one ormore of its local DNS servers (typically through DHCP).When a host makes a DNS query, the query issent to the local DNS server, which acts a proxy, forwarding the query into the DNSserver hierarchy.
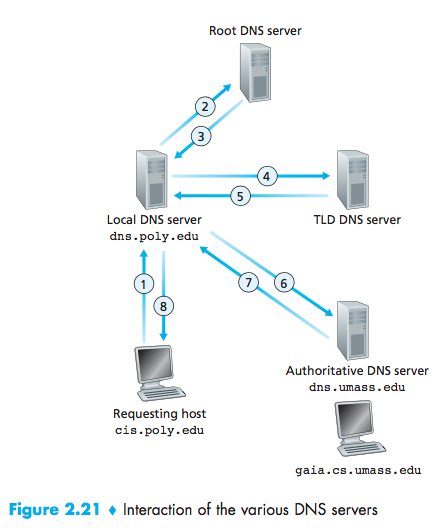
recursive queries and iterative queries:The query sent from cis.poly.edu to dns.poly.edu is a recursive query, Others are iterative.
DNS Caching
In a query chain, when aDNS server receives a DNS reply, it can cache the mapping in its local memory.
DNS servers discard cachedinformation after a period of time (often set to two days).
DNS Records and Messages
the DNS distributed database store resource records (RRs), which provide hostname-to-IP address mappings.
Aresource record is a four-tuple that contains the following fields:
1 | (Name, Value, Type, TTL) |
TTL is the time to live of the resource record; it determines when a resource shouldbe removed from a cache.
- If Type=A, then Name is a hostname and Value is the IP address for the host-name. Thus, a Type A record provides the standard hostname-to-IP address map-ping. As an example, (relay1.bar.foo.com, 145.37.93.126, A)is a Type Arecord;
- If Type=NS, then Name is a domain (such as foo.com) and Value is the host-name of an authoritative DNS server that knows how to obtain the IP addressesfor hosts in the domain. This record is used to route DNS queries further along in the query chain. As an example, (foo.com, dns.foo.com, NS) is a TypeNS record;
- If Type=CNAME, then Value is a canonical hostname for the alias hostnameName. This record can provide querying hosts the canonical name for a host-name. As an example, (foo.com, relay1.bar.foo.com, CNAME) is aCNAME record;
- If Type=MX, then Value is the canonical name of a mail server that has an aliashostname Name. As an example, (foo.com, mail.bar.foo.com, MX)is an MX record. MX records allow the hostnames of mail servers to have simple aliases. Note that by using the MX record, a company can have the samealiased name for its mail server and for one of its other servers (such as its Webserver). To obtain the canonical name for the mail server, a DNS client wouldquery for an MX record; to obtain the canonical name for the other server, the DNS client would query for the CNAME record.
DNS Messages
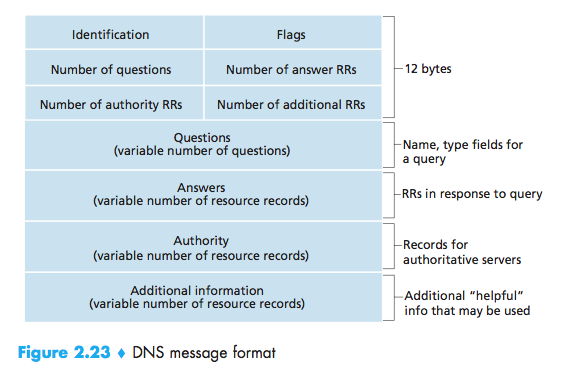
- The first 12 bytes is the header section.
- The first field is a 16-bit number that identifies the query. This identifier is copied into the reply message to a query, allowing the client to match received replies with sent queries.
- There are a number of flags in the flag field. A 1-bit query/reply flag indicates whether the message is a query (0) or a reply (1). A 1-bit authoritative flag is set in a reply message when a DNS server is an authoritative server for a queried name. A 1-bit recursion-desired flag is set when a client (host or DNS server) desires that the DNS server perform recursion when it doesn’t have the record. A 1-bit recursion- available field is set in a reply if the DNS server supports recursion.
- There are also four number-of fields. These fields indicate the number of occurrences of the four types of data sections that follow the header.
- The question section contains information about the query that is being made. This section includes (1) a name field that contains the name that is being queried, and (2) a type field that indicates the type of question being asked about the name—for example, a host address associated with a name (Type A) or the mail server for a name (Type MX);
- In a reply from a DNS server, the answer section contains the resource records for the name that was originally queried. Recall that in each resource record there is the Type (for example, A, NS, CNAME, and MX), the Value, and the TTL. A reply can return multiple RRs in the answer, since a hostname can have multiple IP addresses (for example, for replicated Web servers, as discussed earlier in this section);
- The authority section contains records of other authoritative servers;
- The additional section contains other helpful records. For example, the answer field in a reply to an MX query contains a resource record providing the canonical hostname of a mail server. The additional section contains a Type A record providing the IP address for the canonical hostname of the mail server.
Inserting Records into the DNS Database
A registrar is a commercial entity that verifies the uniqueness of the domain name,enters the domain name into the DNS database.
1 | (networkutopia.com, dns1.networkutopia.com, NS) |
More recently, an UPDATE option has been added to the DNS protocol to allow data to be dynamically added or deleted from the database via DNS messages.
DNS Vulnerabilities
- A DDoS bandwidth-flooding attack against DNS servers. For example, an attacker could attempt to send to each DNS root server a deluge of packets, so many that the majority of legitimate DNSqueries never get answered;
- In a man-in-the-middle attack,the attacker intercepts queries from hosts and returns bogus replies;
- Exploit the DNS infrastructure to launch a DDoS attack against a targeted host.
Peer-to-Peer Applications
P2P File Distribution
In P2P file distribution, each peer can redistribute any portion of the file it has received to any other peers.
Scalability of P2P Architectures
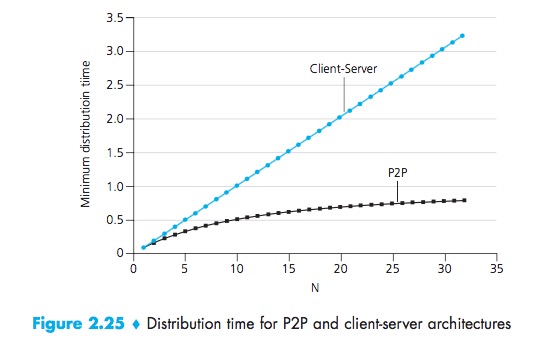
The distribution time is the time it takes to get a copy of the file to all N peers.
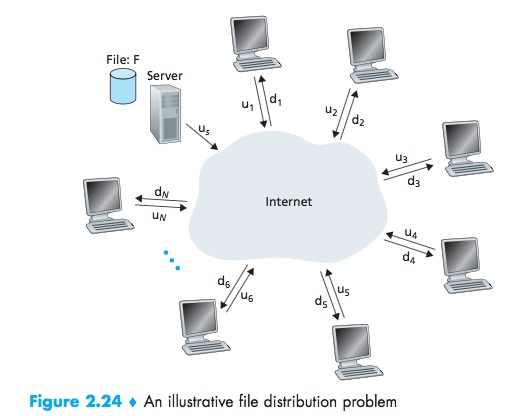
CS:
- The server must transmit one copy of the file to each of the N peers. Thus the server must transmit NF bits;
- Since the server’s upload rate is us, the time to distribute the file must be at least NF/Us;
- The peer with the lowest download rate cannot obtain all F bits of the file in less than F/dmin seconds:
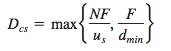
P2P:
- At the beginning of the distribution, only the server has the file,the minimum distribution time is at least F/Us;
- the peer with the lowest download rate cannot obtain all F bits of the file in less than F/dmin seconds;
- Observe that the total upload capacity of the system as a whole is equal to the upload rate of the server plus the upload rates of each of the individual peers, that is, utotal = us + u1 + … + uN. The system must deliver (upload) F bits to each of the N peers, thus delivering a total of NF bits. This cannot be done at a rate faster than utotal. Thus, the minimum distribution time is also at least
NF/(us + u1 + … + uN):
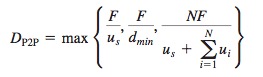
BitTorrent
BitTorrent is a popular P2P protocol for file distribution.
- the collection of all peers participating in the distribution of a particular file is called a torrent;
- Peers in a torrent download equal-size chunks of the file from one another, with a typical chunk size of 256 KBytes.
- While it downloads chunks it also uploads chunks to other peers.
- Each torrent has an infrastructure node called a tracker. When a peer joins a torrent, it registers itself with the tracker and periodically informs the tracker that it is still in the torrent.
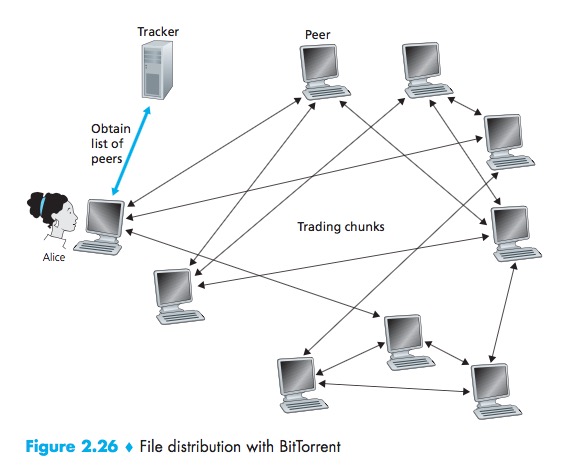
Process:
- When a new peer, A, joins the torrent, the tracker randomly selects a subset of peers from the set of participating peers, and sends the IP addresses of these peers to Alice;
- Possessing this list of peers, A attempts to establish concurrent TCP connections with all the peers on this list;
- As time evolves, some of these peers may leave and other peers may attempt to establish TCP connections with A. So a peer’s neighboring peers will fluctuate over time;
- At any given time, each peer will have a subset of chunks from the file, with different peers having different subsets. Periodically, A will ask each of her neighboring peers (over the TCP connections) for the list of the chunks they have. If A has L different neighbors, she will obtain L lists of chunks. With this knowledge, A will issue requests (again over the TCP connections) for chunks she currently does not have;
- Rarest first:The idea is to determine, from among the chunks she does not have, the chunks that are the rarest among her neighbors (that is, the chunks that have thefewest repeated copies among her neighbors) and then request those rarest chunksfirst;
- a clever trading algorithm:The basic idea is that A gives priority to the neighbors that are currently supplying her data at the highest rate. Specifically, for each of her neighbors,A continually measures the rate at which she receives bits and determines the four peers that are feeding her bits at the highest rate. She then reciprocates by sending chunks to these same four peers. Every 10 seconds, she recalculates the rates and pos- sibly modifies the set of four peers. In BitTorrent lingo, these four peers are said to be unchoked.Every 30 seconds, she also picks one additional neighbor at random and sends it chunks, which is said to be optimistically unchoked.The effect is that peers capable of uploading at compatible ratestend to find each other.
Many of the P2P live streaming applications, such as PPLive and ppstream, have been inspired by BitTorrent.
Distributed Hash Tables (DHTs)
In the P2P system, each peer will only hold a small subset of the totality of the (key, value) pairs. We’ll allow any peer to query the distributed database with a particular key. The distributed database will then locate the peers that have the corresponding (key, value) pairs and return the key-value pairs to the querying peer. Any peer will also be allowed to insert new key-value pairs into thedatabase. Such a distributed database is referred to as a distributed hash table(DHT).
- assign an identifier to each peer, where each identifier is an integer in the range [0, 2n 1] for some fixed n;
- use a hash function that maps each key (e.g., social security number) to an integer in the range [0, 2^n-1];
- the closest peer as the closest successor of the key;
- if the key is exactly equal to one of the peer identifiers, we store the (key, value) pair in that matching peer; and if the key is larger than all the peer identifiers, we use a modulo-2n con- vention, storing the (key, value) pair in the peer with the smallest identifier;
Circular DHT
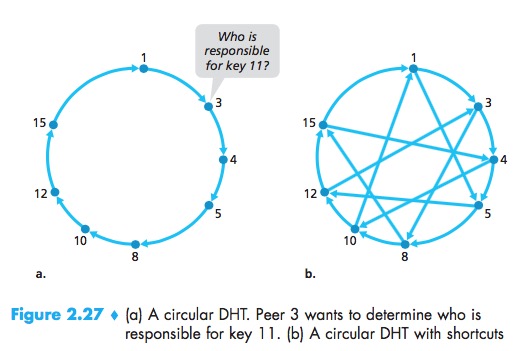
This circular arrangement of the peers is a special case of an overlay network. In an overlay network, the peers form an abstract logical network which resides above the “underlay” computer network consisting of physical links, routers, and hosts.
Using the circular overlay, the origin peer (peer 3) creates a message saying “Who is responsible for key 11?” and sends this message clockwise around the circle, this process continues until the message arrives at peer 12, it send a message back to the querying peer.
In designing a DHT, there is tradeoff between the number of neighbors each peer has to track and the number of messages that the DHT needs to send to resolve a single query:
- use the circular overlay as a foundation, but add “shortcuts” so that each peer not only keeps track of its immediate successor and predecessor, but also of a relatively small number of shortcut peers scattered about the circle;
- so that both the number of neighbors per peer as well as the number of messages per query is O(log N), where N is the number of peers.
Peer Churn
To handle peer churn:
- we will now require each peer to track (that is, know the IP address of) its first and second successors;
- we also require each peer to periodically verify that its two successors are alive;
- suppose peer 5 abruptly leaves, Peers 4 and 3 thus need to update their successor state information;
- a peer wants to join the DHT, it send peer 1 a message, this message gets forwarded through the DHT until it reaches the right one, and it sends this predecessor and successor information to peer.