MySQL 索引存储引擎 InnoDB
索引存储引擎
InnoDB
B+Tree 叶节点的 data 域存放的就是行数据,这被称为“聚簇索引(聚集索引)”
- 表数据文件本身就是主索引
- user 表的数据和索引存储在 t_user_innodb.ibd 文件中
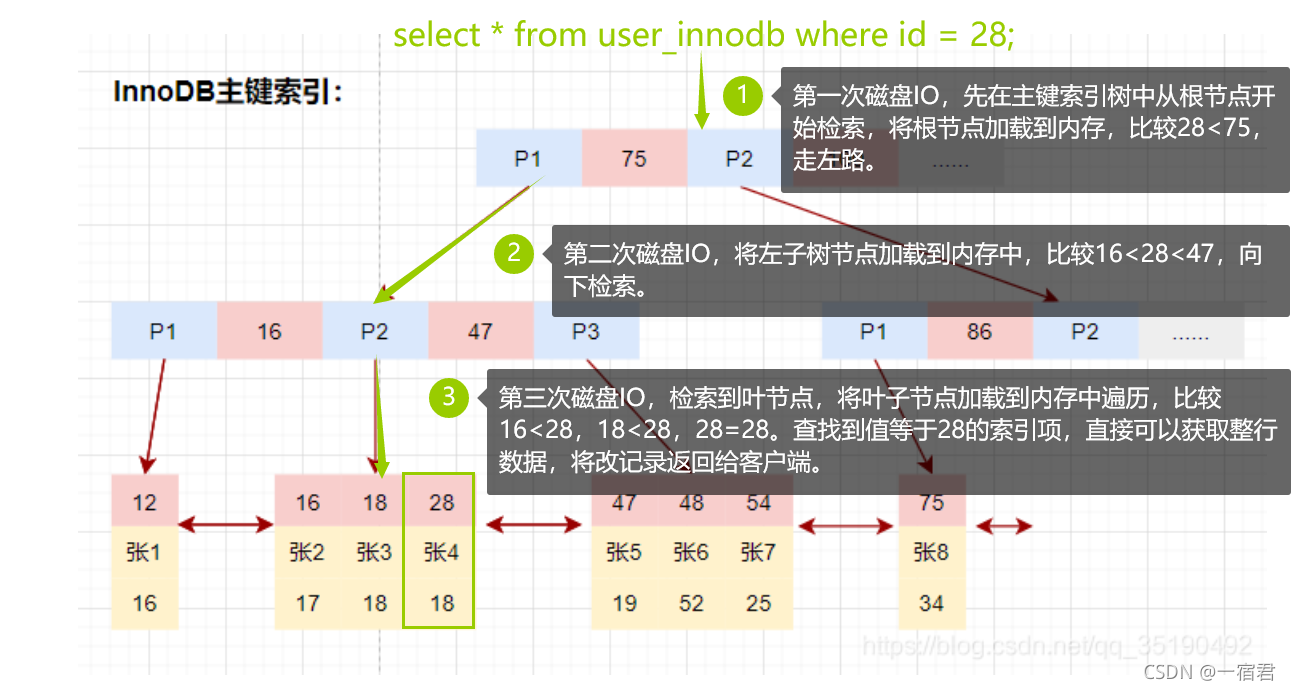
检索流程
- 在根据主索引搜索时,直接找到Key所在的节点即可取出数据
注意:在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂 - 在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引
举例:
1 | CREATE TABLE `user_innodb` |
磁盘IO次数:三次
创建索引的具体规则
- 在创建表时,定义主键 Primary Key,InnoDB 会自动将主键索引用作聚簇索引
- 如果表没有定义主键,InnoDB 会选择第一个不为 NULL 的唯一索引列用作聚簇索引
- 如果以上两个都没有,InnoDB 会自动使用一个长度为 6 字节的 RowID 字段来构建聚簇索引,该 RowID 字段会在插入新的行记录时自动递增
辅助索引
在 InnoDB 中,辅助索引中的叶子节点键值存储的是该行的主键值
回表查询
- 在辅助索引树中获取到主键id,再根据主键id到主键索引数中检索数据的的过程
- 在数据量比较大的时候,回表必然会消耗很多的时间影响性能,所以我们要尽量避免回表的发生
举例:
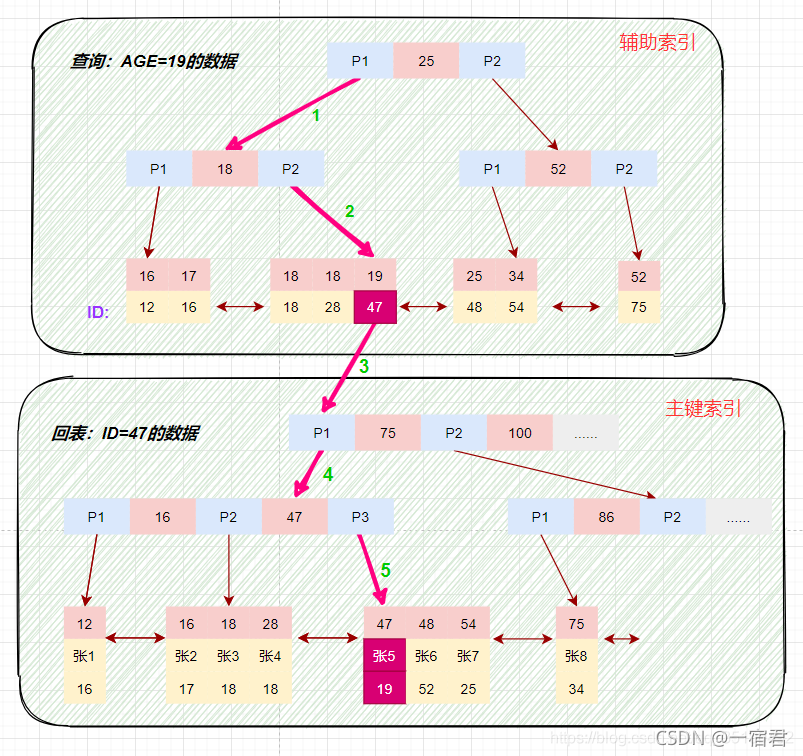
磁盘IO数(从根节点开始):辅助索引 3 次 + 回表过程 3 次
组合索引
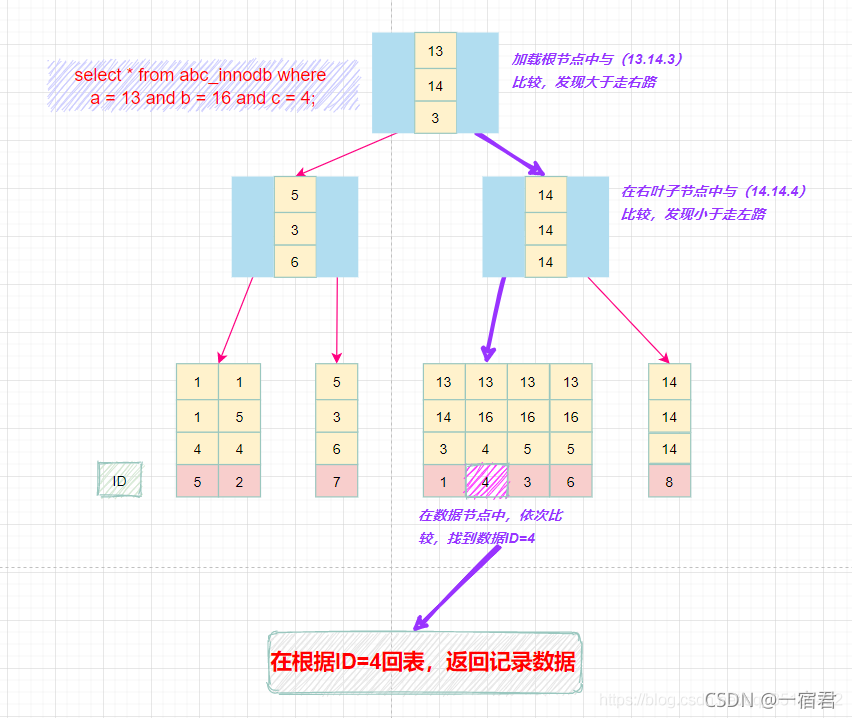
最左匹配原则
- 最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的
- 在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排序,但是b列和c列是无序的
- B+ 树会先比较a列来确定下一步应该检索的方向,往左还是往右。如果a列相同再比较b列,但是如果查询条件中没有a列,B+树就不知道第一步应该从那个节点开始查起
- b列只有在a列值相等的情况下小范围内有序递增
- 而c列只能在a和b两列值相等的情况下小范围内有序递增
- 在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排序,但是b列和c列是无序的
- 可以说创建的 idx_(a,b,c) 索引,相当于创建了 (a)、(a,b)、(a,b,c) 三个索引
举例:
1 | CREATE TABLE `abc_innodb` |
创建原则
- 在创建联合索引的时候应该把频繁使用的列、区分度高的列放在前面
- 频繁使用代表索引利用率高,区分度高代表筛选力度大
- 将常需要作为查询返回的字段增加到联合索引中
- 如果在联合索引上增加了一个字段,而恰好满足了使用覆盖索引的情况,这种情况建议使用联合索引
优点
- 联合索引的使用不仅可以节省空间,还可以更容易的使用到覆盖索引
- 比如联合索引(a,b,c)等于有了:a、(a,b)、(a,b,c)三个索引,这样就节省了空间,当然节省的空间并不是三倍于a、(a,b)、(a,b,c)三个索引所占用的空间,但是联合索引中data字段数据所占用的空间确实节省了不少
覆盖索引
查询的值就是索引,那么不需要去检索到叶子节点,直接返回找到的索引就行
使用覆盖索引可以减少回表查询
举例:
1 | select id,name,sex from user where name = 'zhangsan'; |
在这个情况下,如果我们在建立name字段的索引时,不是使用单一索引,而是使用联合索引(name,sex), 这样的话再执行这个查询语句,根据这个辅助索引(name,sex)查询到的索引就是要的结果,不需要再去回表查询